Key takeaways
- AI Share of Voice (AI SoV) measures how often your brand is cited in AI-generated answers compared to competitors -- it's a different metric from traditional search rankings and requires different tools to track
- The basic formula is simple: (your brand citations ÷ total citations across tracked prompts) × 100
- Most brands are invisible in AI answers even when they rank well in Google -- the two don't always correlate
- Benchmarking requires picking the right prompts, tracking across multiple AI models, and separating mention-based SoV from citation-based SoV
- Growing your AI SoV is an active process: find the content gaps, create content AI models want to cite, then track whether it's working
If you asked someone to define "share of voice" five years ago, the answer was pretty simple: what percentage of Google's first page does your brand own for the keywords that matter? That was the whole game.
In 2026, that answer is incomplete. Not wrong -- Google still drives the overwhelming majority of search traffic. But AI search has added a layer on top of the traditional funnel that didn't exist before, and brands that ignore it are losing influence at the exact moment buyers are forming opinions.
This guide walks through what AI Share of Voice actually is, how to measure it properly, how to benchmark against competitors, and -- most importantly -- what to do when the numbers aren't good.
What AI share of voice actually means
AI Share of Voice measures how often your brand appears in AI-generated responses compared to your competitors, across a defined set of prompts.
The math isn't complicated:
AI SoV = (Your brand citations ÷ Total brand citations tracked) × 100
So if you're tracking 100 prompts and your brand gets cited in 23 of them, while competitors collectively get cited in 77, your AI SoV is 23%.
But the number alone doesn't tell you much. Context matters:
- Which prompts are you winning? Informational queries? Comparison queries? Bottom-of-funnel recommendations?
- Which AI models are citing you? A brand might dominate in Perplexity but be invisible in ChatGPT.
- Are you a primary citation (the main source) or a secondary reference (mentioned in passing)?
- Are you being mentioned positively, neutrally, or not at all?

The distinction between mention-based SoV and citation-based SoV is worth understanding early. Mention-based SoV counts how often your brand name appears in AI responses. Citation-based SoV counts how often your actual web pages are linked or referenced as sources. Both matter, but they tell different stories. You can have high mention-based SoV (people ask about you, AI talks about you) but low citation-based SoV (AI isn't actually pulling from your content). That gap usually means your content isn't structured in a way AI models can easily use.
Why this metric matters now
Traditional search rankings were a proxy for market share. If you ranked #1 for "best project management software," you captured a disproportionate share of clicks. The relationship was imperfect but directional.
AI search breaks that proxy. When ChatGPT or Perplexity answers a question, it synthesizes a single response from multiple sources. There's no position 1 through 10. There's "cited" or "not cited." Being absent from that response means being invisible to the user at the moment they're deciding -- and they may never visit a search results page at all.
BrightEdge's AI Market Pulse data puts this in perspective: Google still handles over 90% of search traffic, and AI platforms account for less than 1% of direct referrals. But that framing misses the point. AI search isn't primarily a traffic channel yet -- it's a discovery and influence channel. Users ask AI questions, form opinions, and then convert through organic search or direct. If your brand isn't shaping that early conversation, you're starting the funnel behind.
How to set up AI share of voice benchmarking
Step 1: Define your prompt set
This is where most teams go wrong. They either track too few prompts (and get a misleading picture) or too many generic ones (and get noise).
A good prompt set for AI SoV benchmarking should include:
- Category-level queries: "What's the best [product category]?" or "How do I choose a [solution type]?"
- Comparison queries: "[Your brand] vs [Competitor A]" and "[Competitor A] vs [Competitor B]"
- Problem-based queries: "How do I solve [specific pain point]?"
- Recommendation queries: "Which [product] should I use for [use case]?"
- Brand-specific queries: Direct questions about your brand and competitors
Aim for 50-150 prompts depending on your market. Fewer than 50 and you're working with a sample too small to be reliable. More than 200 and you'll struggle to act on the data.
Step 2: Choose which AI models to track
Different AI models have different citation behaviors. ChatGPT tends to be more conservative with citations. Perplexity is citation-heavy by design. Google AI Overviews pulls heavily from pages that already rank well in traditional search. Claude and Gemini have their own patterns.
At minimum, track ChatGPT, Perplexity, and Google AI Overviews. These three cover the majority of AI search volume. Add Claude, Gemini, and Grok if your audience is more technical or if you're in a category where those models are commonly used.
Step 3: Decide how to collect the data
You have two options: manual or automated.
Manual tracking means running each prompt through each AI model, recording responses, and logging citations in a spreadsheet. It's free, but it doesn't scale. A 100-prompt set across 5 models is 500 individual queries, and you need to repeat this regularly to see trends.
Automated tracking uses a dedicated platform to run prompts at scale, log responses, and calculate SoV metrics automatically. This is the only realistic approach for ongoing benchmarking.
Promptwatch handles this across 10 AI models simultaneously -- ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini, Grok, DeepSeek, Meta AI, Copilot, and Mistral. It tracks which pages are being cited, how often, and by which model, so you can see your SoV broken down by model and by prompt category rather than as a single aggregate number.

Other tools worth knowing about:


Step 4: Set your baseline
Before you can benchmark against competitors, you need a baseline for yourself. Run your prompt set, collect the data, and record:
- Overall AI SoV percentage
- SoV by AI model
- SoV by prompt category (informational vs. comparison vs. recommendation)
- Which specific pages are being cited
- Which prompts you're completely absent from
That last one -- the prompts where you don't appear at all -- is your most actionable data point.
Competitive benchmarking: how to read the data
Once you have your own baseline, add your top 3-5 competitors to the same prompt set. Now you can see the full picture.

A useful way to structure competitive analysis is by prompt type:
| Prompt category | Your SoV | Competitor A | Competitor B | Gap |
|---|---|---|---|---|
| Category queries | 18% | 34% | 22% | -16% vs leader |
| Comparison queries | 31% | 28% | 19% | +3% vs leader |
| Problem-based queries | 9% | 41% | 27% | -32% vs leader |
| Recommendation queries | 22% | 29% | 18% | -7% vs leader |
This kind of breakdown tells you where to focus. If you're losing badly on problem-based queries, that's a content gap -- you probably don't have enough content that directly addresses the problems your customers have. If you're winning on comparison queries, that's a signal your comparison content is working and worth expanding.
What the heatmap view reveals
Most dedicated AI SoV tools will show you a heatmap: your brand vs. competitors across each prompt. The prompts where a competitor consistently appears and you don't are your highest-priority gaps. These aren't just prompts where you're losing -- they're prompts where buyers are asking questions and your brand isn't part of the answer.

The three things that drive AI share of voice
Understanding what influences AI citations helps you prioritize where to invest.
Content coverage
AI models can only cite what they can find and understand. If you don't have content that addresses a specific question, you won't appear in answers to that question. This sounds obvious, but most brands have significant coverage gaps -- topics their competitors have written about that they haven't touched.
The fix is content gap analysis: systematically identifying which prompts your competitors are visible for that you're not, then creating content to fill those gaps. This is different from traditional keyword gap analysis because you're looking at what AI models are actually citing, not just what ranks in Google.
Content structure and clarity
AI models prefer content that's easy to extract and reuse. Long, meandering articles with buried answers are harder to cite than content with clear headings, direct answers, and well-organized information. Structured data (FAQ schema, HowTo schema) helps. Short, direct answers to specific questions help. Content that reads like it was written for a human who wants a clear answer -- not for a search engine that rewards keyword density -- tends to perform better.
Authority and trust signals
AI models weight sources they perceive as authoritative. This includes traditional signals like backlinks and domain authority, but also factors like how often a source is cited by other sources, whether the brand appears in credible third-party publications, and whether the content is consistent and accurate over time. Reddit threads, YouTube videos, and industry publications all influence what AI models consider trustworthy -- which is why tracking those channels matters alongside your own site.
Turning benchmarking data into action
Benchmarking without action is just expensive reporting. Here's how to close the loop.
Prioritize gaps by prompt volume and difficulty
Not all gaps are equal. A prompt that gets asked thousands of times per month is worth more than one that gets asked a dozen times. Before you start creating content, rank your gaps by estimated prompt volume and by how competitive the current citation landscape is. High-volume, low-competition gaps are where you'll see the fastest SoV gains.
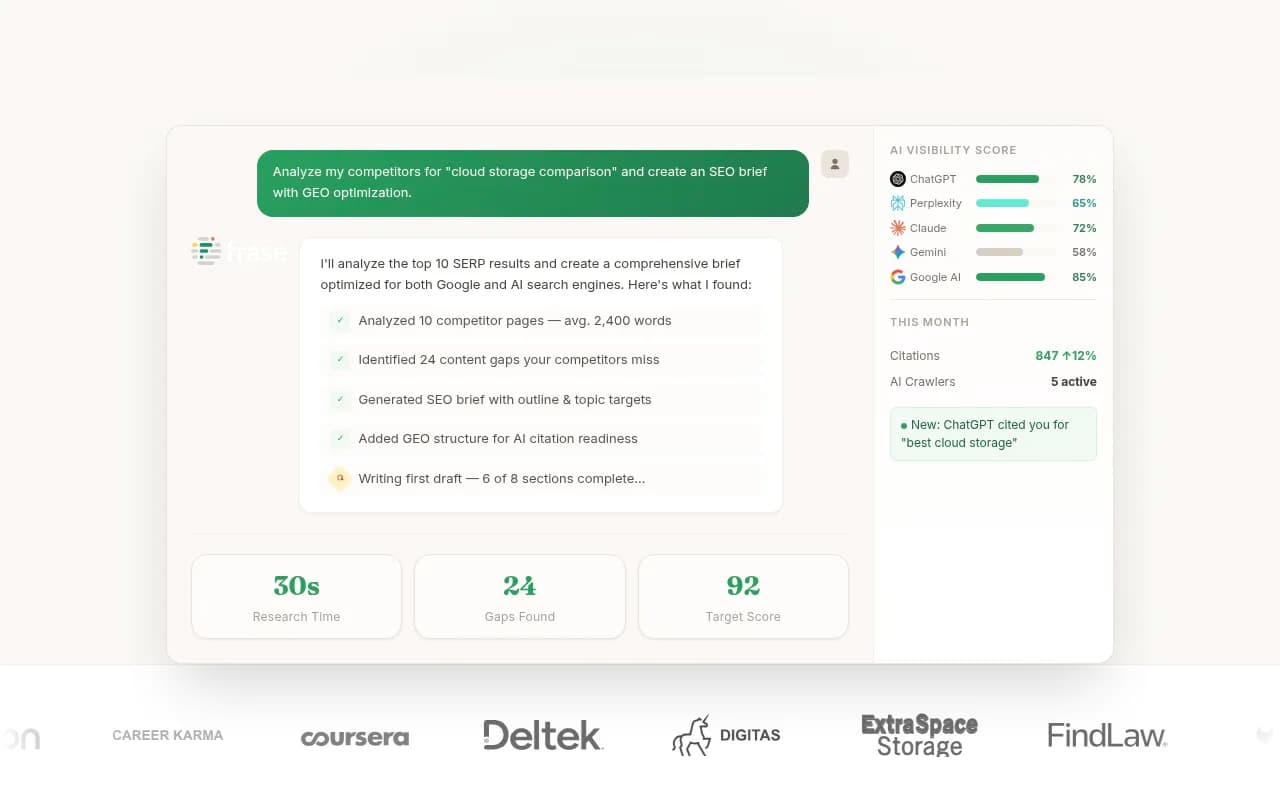
Create content specifically for AI citation
Content that gets cited by AI models tends to share certain characteristics: it directly answers the question in the first few paragraphs, it's comprehensive enough to be the definitive source, it uses clear structure, and it's regularly updated. Generic blog posts written for keyword stuffing rarely get cited. Specific, authoritative, well-structured content does.
Tools like Promptwatch have built-in AI writing agents that generate content grounded in actual citation data -- meaning the content is designed around what AI models are already citing, not just what ranks in Google. That's a meaningful difference when your goal is AI visibility specifically.
Other content tools that can help:
Fix technical issues that block AI crawlers
AI models crawl your site to discover and index your content. If they're hitting errors, running into blocked pages, or finding content that's slow to load, they may not be reading your best material at all. Monitoring which pages AI crawlers are actually visiting -- and which ones they're skipping -- is a diagnostic step most brands overlook entirely.
Track results and iterate
After publishing new content, monitor whether your AI SoV improves on the prompts you targeted. This isn't instant -- it can take weeks for AI models to discover, index, and start citing new content. But the trend should be visible within a month or two. If a piece of content isn't getting cited after 6-8 weeks, look at whether it's actually answering the prompt directly, whether it's structured clearly, and whether AI crawlers are actually reaching it.
Common benchmarking mistakes to avoid
Tracking too few prompts. A 20-prompt set will give you a misleading picture. You need enough prompts to represent the full range of questions your customers ask.
Only tracking one AI model. Your SoV in ChatGPT and your SoV in Perplexity can look completely different. Aggregate numbers hide model-specific patterns.
Confusing mentions with citations. Being mentioned in an AI response ("some people recommend Brand X") is different from being cited as a source. Both matter, but they require different fixes.
Ignoring prompt intent. A high SoV on informational queries but zero presence on recommendation queries means you're educating buyers but not converting them. Intent matters.
Not tracking competitors consistently. Competitive benchmarking only works if you track the same competitors across the same prompts over time. Ad hoc checks don't reveal trends.
Tools for AI share of voice benchmarking in 2026
Here's a quick comparison of the main options:
| Tool | AI models tracked | Content gap analysis | AI content generation | Crawler logs | Best for |
|---|---|---|---|---|---|
| Promptwatch | 10 | Yes | Yes | Yes | End-to-end optimization |
| Conductor | Multiple | Partial | No | No | Enterprise monitoring |
| Profound | Multiple | Limited | No | No | Brand tracking |
| Otterly.AI | Multiple | No | No | No | Basic monitoring |
| Peec AI | Multiple | No | No | No | Multi-language tracking |
| Rankscale | Multiple | No | No | No | Rank tracking |
The core difference between these tools is whether they stop at monitoring or help you act. Most platforms will show you your SoV number and a competitor heatmap. Fewer will tell you specifically what content to create. Fewer still will help you create it and then track whether it worked.
Where to start if you're doing this for the first time
Pick 50 prompts that represent the questions your customers actually ask. Run them through ChatGPT, Perplexity, and Google AI Overviews. Record which brands appear and how often. Calculate your SoV. Find the prompts where competitors appear and you don't.
That list of gaps is your content roadmap.
Start with the gaps that are highest-volume and where the current AI responses are weakest -- vague, generic, or pulling from low-quality sources. Those are the easiest wins. Write content that directly addresses those questions, structure it clearly, and make sure AI crawlers can reach it.
Then measure again in 4-6 weeks. Adjust based on what's working.
AI Share of Voice isn't a metric you optimize once. It's a continuous process -- find gaps, fill them, track the results, find the next gaps. The brands that build that loop into their regular workflow are the ones that will compound their AI visibility over time while competitors are still trying to figure out what to measure.