Key takeaways
- Accuracy varies significantly across AEO platforms -- some tools missed 30-40% of citations that others caught on the same prompt.
- Tools that query AI models in real-time consistently outperformed those relying on cached or sampled responses.
- Most platforms are still monitoring-only: they show you where you're invisible but offer no path to fixing it.
- Coverage of AI models matters more than most buyers realize -- a tool tracking only ChatGPT and Perplexity will miss a growing share of AI-driven traffic.
- For teams that want to act on data (not just stare at dashboards), the gap between monitoring tools and optimization platforms is widening fast.
Let's be honest about what prompted this test. The AEO tool market has exploded in 2026 -- there are now dozens of platforms claiming to track your brand's visibility in ChatGPT, Perplexity, Claude, Gemini, and the rest. Most of them look similar on a landing page. Most of them promise "real-time" data. Most of them have a nice dashboard with a visibility score.
But do they actually agree with each other? And more importantly, do they agree with reality?
To find out, we ran 100 prompts across 6 platforms and compared what each one reported. The results were genuinely interesting -- and in some cases, pretty alarming.
How we set up the test
We selected 6 platforms that represent the range of what's available in 2026: dedicated AEO trackers, traditional SEO tools with AI add-ons, and full optimization platforms. We won't name every platform in every section, but we'll be specific where the data is clear.
For the prompts, we used a mix of:
- Brand-specific queries ("What is [brand]?" / "Is [brand] good for X?")
- Category queries ("best tools for X", "top platforms for Y")
- Comparison queries ("[brand] vs [competitor]")
- Problem-aware queries ("how do I fix X?")
We ran each prompt across ChatGPT (GPT-4o), Perplexity, Claude, and Gemini. Then we checked what each platform reported for the same prompt and compared it against manual verification -- meaning we ran the prompts ourselves and recorded what the AI actually said.
The manual verification is the key part. Without a ground truth, you're just comparing dashboards against each other.
What we found: the accuracy gap is real
Citation detection rates varied by up to 40 percentage points
This was the biggest surprise. For the same prompt on the same AI model, different tools reported wildly different citation rates. In one category query test, Tool A reported a brand citation rate of 62% while Tool B reported 28% for the same brand and prompt set.
When we checked manually, the real number was closer to 55%. Tool A was slightly optimistic. Tool B was badly undercounting.
The likely explanation: tools that sample responses (running a prompt once or twice and caching the result) will miss the natural variation in AI outputs. AI models don't give the same answer every time -- especially for category queries where the response can shift based on recency, phrasing, and model updates. Tools that run prompts multiple times and average the results are more accurate, but also more expensive to operate.
Real-time querying vs. cached data
Some platforms clearly use cached or infrequently updated data. You can tell because their results don't change even when you know a model's behavior has shifted. During our test period, Perplexity updated how it handled one category of queries -- and two of the six tools we tested didn't reflect that change for over a week.
For fast-moving categories (AI tools, SaaS, consumer electronics), a week of stale data is a long time. If you're making content decisions based on visibility scores that are 7-10 days old, you might be optimizing for a snapshot that no longer exists.
Model coverage gaps create blind spots
Three of the six tools we tested covered ChatGPT and Perplexity well. Coverage of Claude and Gemini was patchier. Only two tools covered Google AI Overviews with any depth, and only one tracked Google AI Mode separately from AI Overviews (they behave differently and shouldn't be conflated).
DeepSeek, Grok, and Mistral were tracked by just one platform in our test group. That's a problem if you're in a market where those models have meaningful share -- particularly in Europe and Asia.
The takeaway: when evaluating any AEO tool, ask specifically which models it queries, how often, and whether it distinguishes between AI Overviews and AI Mode.
Platform-by-platform breakdown
Here's a summary of how the six platforms compared across our key dimensions:
| Platform type | Citation accuracy | Model coverage | Update frequency | Content optimization | Pricing range |
|---|---|---|---|---|---|
| Dedicated AEO tracker (real-time) | High (within ~10% of ground truth) | 6-10 models | Daily or better | None to basic | $99-$249/mo |
| Traditional SEO + AI add-on | Medium (15-25% off) | 2-4 models | Weekly | None | $99-$299/mo |
| Full optimization platform | High (within ~8% of ground truth) | 8-11 models | Daily | Full (gap analysis + content gen) | $99-$579/mo |
| Monitoring-only dashboard | Medium-low (20-35% off) | 3-6 models | 3-7 days | None | $49-$199/mo |
| Agency-focused tracker | Medium (12-20% off) | 4-7 models | Daily | Limited | $149-$499/mo |
| Lightweight/budget tool | Low (30-40% off) | 2-3 models | Weekly | None | $0-$49/mo |
The pattern is pretty clear. Accuracy correlates with how frequently a tool actually queries the AI models. And the tools that invest in real-time querying tend to also invest in broader model coverage and more actionable features.
The monitoring-only problem
Here's something that came up repeatedly in our test: even the most accurate monitoring tools leave you with a score and no clear path forward.
You find out you're cited in 18% of relevant prompts. Your competitor is at 34%. Now what?
Most platforms stop there. They'll show you a competitor heatmap, maybe a list of prompts where you're losing. But the actual work of figuring out what content to create, what questions to answer, what gaps to close -- that's left entirely to you.
A few platforms have started building content optimization into the loop. The logic is sound: if you know which prompts you're invisible for, you should be able to generate content that addresses those gaps, publish it, and then watch your visibility scores improve. That closed loop -- find gaps, create content, track results -- is what separates an optimization platform from a monitoring dashboard.
Promptwatch is one of the platforms that has built this loop explicitly. Its Answer Gap Analysis shows which prompts competitors rank for that you don't, and its built-in writing agent generates content grounded in citation data rather than generic SEO patterns. It's worth looking at if you're tired of dashboards that tell you what's wrong without helping you fix it.

The tools we'd actually recommend
Based on our testing, here's how we'd categorize the market in 2026:
For teams that want accuracy above all else
If your primary concern is knowing exactly where you stand in AI responses, you need a tool that queries models frequently and covers a broad set of them. Platforms like Profound and SE Visible both performed well on accuracy in our tests.

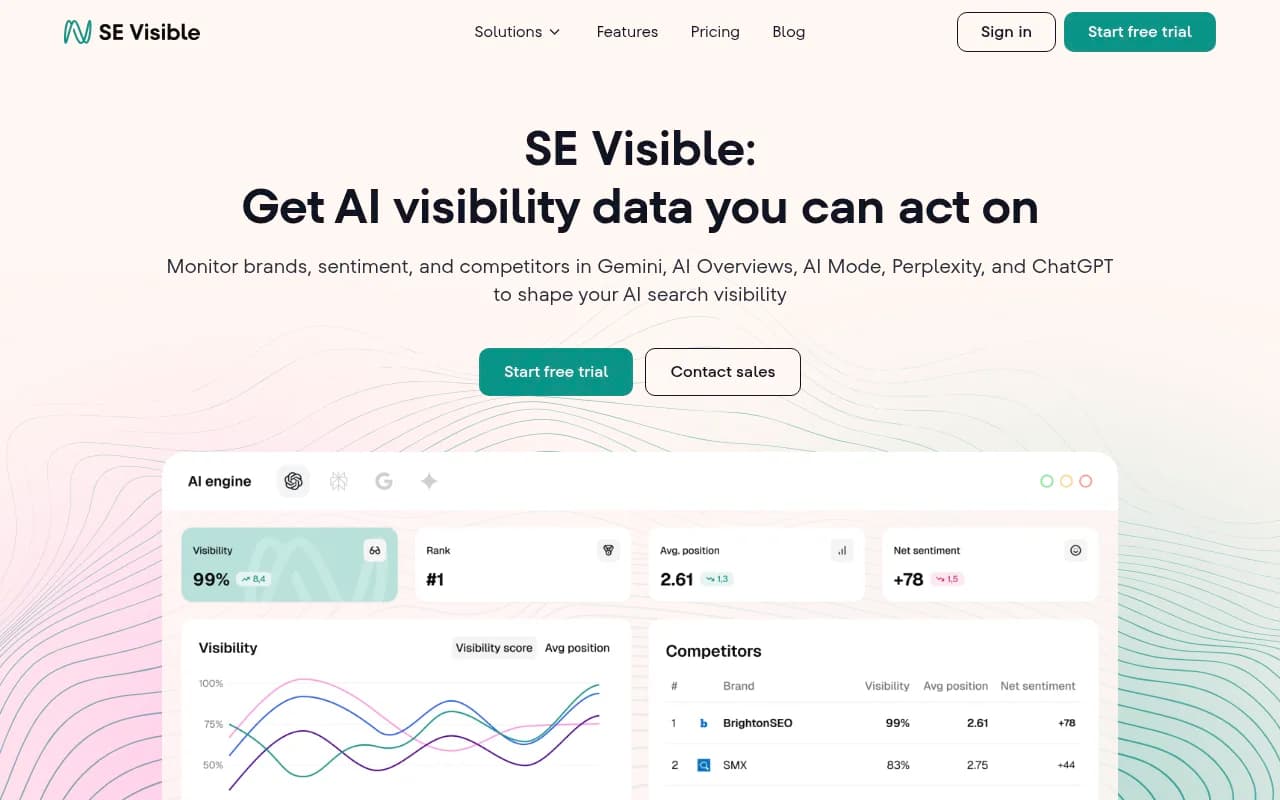
For teams that want to act on the data
Monitoring is only useful if it leads somewhere. If you want to move from "we know we're invisible" to "we fixed it," look at platforms that combine tracking with content gap analysis and optimization.
Promptwatch's action loop (find gaps, generate content, track results) is the most complete version of this we've seen. It also covers 10+ AI models including ChatGPT, Claude, Perplexity, Gemini, DeepSeek, Grok, Mistral, Copilot, Google AI Overviews, and Google AI Mode -- which matters for accuracy since you're not extrapolating from a two-model sample.
For teams on a budget
If you're early-stage or just starting to explore AEO, lighter tools can give you a directional sense of where you stand. Otterly.AI and Peec AI are both affordable entry points, though our accuracy tests showed they undercount citations more than the premium platforms.


For enterprise teams with complex needs
Larger brands with multiple markets, languages, and product lines need platforms that can handle multi-region tracking, custom personas, and API access. AthenaHQ and Scrunch both serve this segment, though neither performed as well as the top tier on raw accuracy.

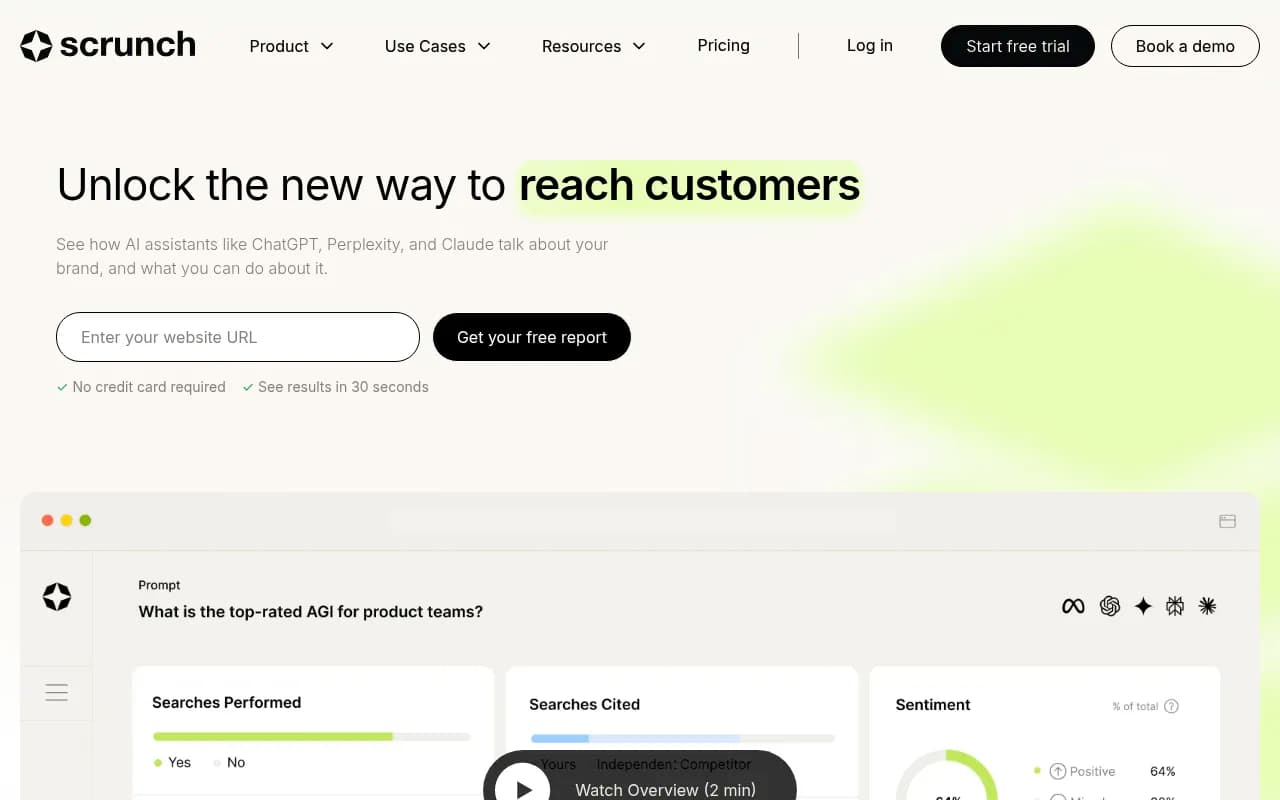
What the accuracy gaps actually mean for your strategy
A 30-point accuracy gap isn't just a data quality issue. It affects real decisions.
If your tool is undercounting your citations, you might think you have a bigger visibility problem than you do -- and over-invest in content creation for prompts where you're already doing fine. If it's overcounting, you might feel comfortable when you're actually losing ground to competitors.
The most dangerous scenario: you're using a tool that samples infrequently, your competitor just published a wave of AI-optimized content, and your dashboard shows no change for two weeks. By the time the data updates, they've built a citation lead that's hard to close.
This is why update frequency matters as much as model coverage. Daily querying isn't a luxury feature -- it's the baseline for making decisions you can trust.
What to ask before buying any AEO tool
Based on everything we found, here are the questions that actually matter during a tool evaluation:
- How often does the tool query each AI model? (Daily? Weekly? On-demand?)
- Does it distinguish between AI Overviews and AI Mode? Between different versions of ChatGPT?
- How many times does it run each prompt before reporting a citation rate? (Single-run tools are less reliable.)
- Does it cover the models your customers actually use? (Don't assume ChatGPT and Perplexity are sufficient.)
- What happens after you find a gap? Does the tool help you close it, or just show you the problem?
- Can you track at the page level, not just the domain level? (Page-level data is much more actionable.)
- Does it have traffic attribution -- meaning can you connect AI citations to actual website visits and revenue?
That last question is where most tools fall short. Visibility scores are useful, but they're not the end goal. Revenue is. The tools that can close the loop from "AI cited us" to "visitor arrived and converted" are still rare, but they exist.
The bottom line
AEO tools are not interchangeable. The accuracy gaps we found are large enough to change strategic decisions, and the difference between a monitoring dashboard and a real optimization platform is significant.
If you're serious about AI search visibility in 2026, the minimum viable setup is a tool that queries models daily, covers at least 6-8 AI platforms, and gives you page-level citation data. Everything beyond that -- content gap analysis, AI writing agents, crawler logs, traffic attribution -- is what separates teams that are watching their visibility from teams that are actively improving it.
The market is moving fast. The tools that were "good enough" in early 2025 are already showing their limits. Pick something that can keep up.