Key takeaways
- DarkVisitors rebranded to Known Agents in late 2025, but the core function remains: identifying and cataloging AI bots visiting your site so you can make informed decisions about blocking or allowing them.
- Server log analysis and tools like Known Agents serve different but complementary purposes -- logs give you raw ground truth, Known Agents gives you context and classification.
- AI-driven traffic nearly tripled in 2025 (187% growth), and agentic AI traffic grew 7,851% year-over-year, according to HUMAN Security's 2026 benchmark report.
- Combining bot identification data with AI visibility platforms gives you the complete picture: not just which bots visited, but whether those visits are translating into citations and referrals.
- Your robots.txt strategy needs a complete overhaul in 2026 -- a blanket "allow all" is no longer a reasonable default.
Why AI bot traffic suddenly matters
For most of the last decade, bot traffic was a nuisance metric. You'd filter it out of Google Analytics, maybe block a few obvious scrapers in robots.txt, and move on. The bots that mattered -- Googlebot, Bingbot -- were well-behaved and well-understood.
That era is over.
HUMAN Security's 2026 State of AI Traffic & Cyberthreat Benchmark Report, which analyzed more than one quadrillion interactions, found that AI-driven traffic grew 187% in 2025. Agentic AI traffic -- bots that don't just crawl but actually take actions -- grew 7,851% year-over-year. Automation is now growing eight times faster than human traffic.
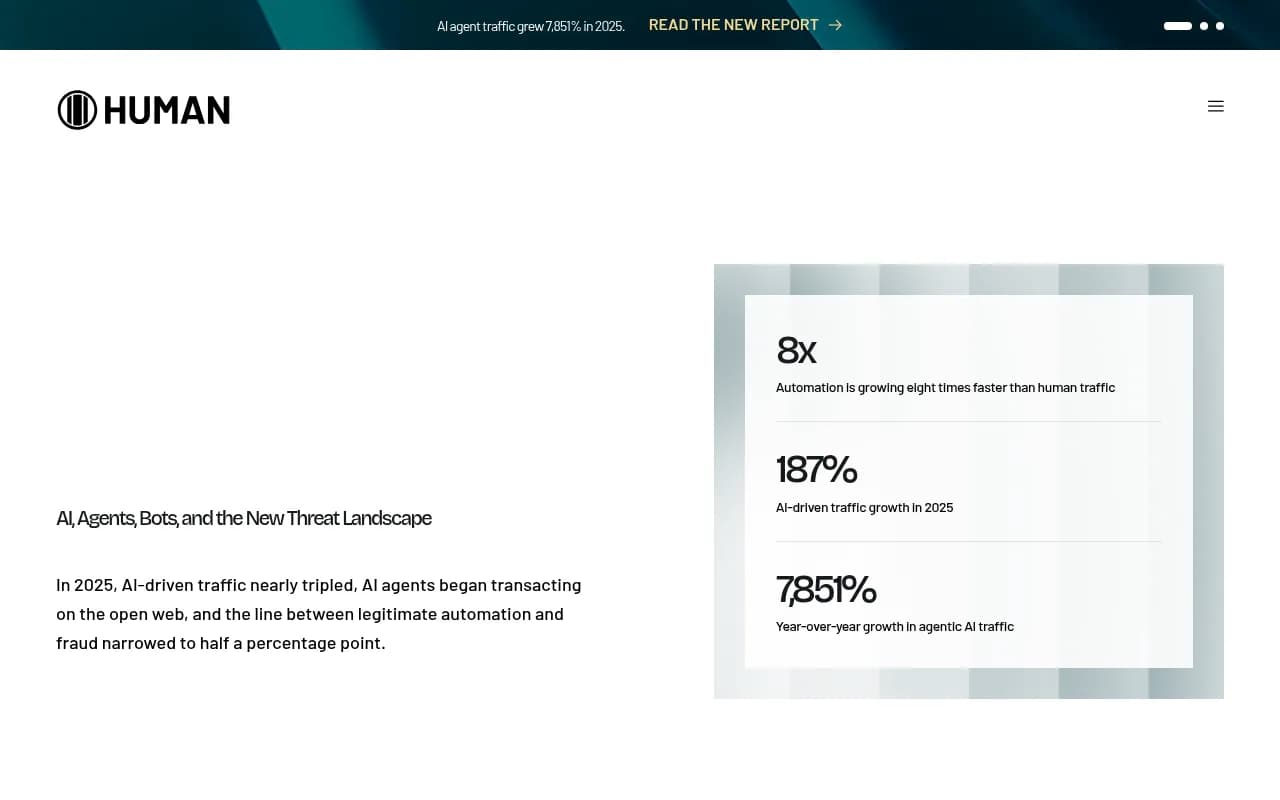
That's not a rounding error. That's a structural shift in what your web server is actually serving. And most site owners have no idea it's happening, because standard analytics tools filter bots out entirely.
The bots hitting your site in 2026 fall into a few distinct categories:
- Training crawlers that scrape content to build or update LLM datasets
- AI search crawlers that index your content to include in AI-generated answers
- Agentic AI systems that browse, click, and transact on behalf of users
- Malicious scrapers that mimic legitimate bot user agents
Each category has different implications for your site. A training crawler consuming your content without permission is a very different problem from an AI search crawler that might cite you in ChatGPT responses. Treating them the same way -- either blocking all or allowing all -- is a mistake.
What DarkVisitors (now Known Agents) actually does
DarkVisitors launched as a database of AI agents and their user agent strings. The premise was simple: if you know which user agents belong to which AI systems, you can make informed decisions in your robots.txt. The tool also offered a JavaScript snippet that would log bot visits directly in a dashboard, without requiring access to raw server logs.
In late 2025, DarkVisitors rebranded to Known Agents. The name change reflects a broader philosophy shift -- from treating AI bots as shadowy unknowns to actively cataloging and classifying them for transparency. The database now covers dozens of AI crawlers across training, search, and agentic categories.
The core value Known Agents provides is classification. When a bot hits your site with a user agent string like GPTBot/1.0 or ClaudeBot, Known Agents tells you:
- Which company operates this bot
- What the bot's stated purpose is (training, search indexing, agentic browsing)
- Whether it respects robots.txt
- What the recommended robots.txt directive is
That last point matters more than it sounds. Not all AI bots respect robots.txt. Some training crawlers will ignore your directives entirely. Knowing this upfront changes your response -- if a bot ignores robots.txt, you need firewall-level blocking, not a polite disallow directive.
The JavaScript snippet approach
For site owners who don't have easy access to server logs (which is most WordPress users, most shared hosting customers, and many teams where the developer controls log access), Known Agents offers a JavaScript-based tracking snippet. Install it, and you get a dashboard showing which AI bots visited your site, which pages they hit, and how frequently.
This is genuinely useful, but it has a real limitation: JavaScript-based tracking only captures bots that execute JavaScript. Many crawlers don't. Raw server logs capture every request, regardless of whether JavaScript ran. So the JavaScript snippet gives you a useful approximation, not a complete count.
The server log approach: more complete, more painful
Server logs are the ground truth of bot activity. Every HTTP request your server receives gets logged -- the timestamp, the IP address, the user agent string, the URL requested, the response code. No bot can hide from a server log (though some do spoof user agents, which is a separate problem).
The challenge is that server logs are:
- Often locked behind hosting provider interfaces
- Enormous (a busy site generates gigabytes of logs per day)
- Formatted for machines, not humans
- Rarely integrated with the tools marketers actually use
Parsing server logs to extract AI bot activity requires either command-line skills, a log analysis tool, or both. Tools like JetOctopus and Screaming Frog can ingest log files and visualize bot activity, but they're built primarily for SEO crawl analysis, not AI bot classification specifically.
The workflow that actually works is a combination: use server logs for completeness, use Known Agents (or a similar classification database) to make sense of what you're seeing. A raw log entry showing Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.1; +https://openai.com/gptbot) is meaningless without context. Known Agents provides that context.
How the two approaches complement each other
Here's the honest picture of what each approach gives you:
| Approach | Coverage | Setup complexity | Classification | Real-time? |
|---|---|---|---|---|
| Known Agents JS snippet | Bots that execute JS | Low (paste snippet) | Yes, automatic | Yes |
| Server log analysis | All bots, all requests | High (log access + parsing) | Manual or via tool | No (batch) |
| Combined approach | All bots | Medium | Yes, automatic | Partial |
| Dedicated crawler log platform | All bots | Low-medium | Yes, automatic | Yes |
The combined approach works like this in practice:
- Install the Known Agents snippet for immediate visibility into JS-executing bots
- Export server logs weekly (or set up a log streaming pipeline if you have the infrastructure)
- Cross-reference log entries against the Known Agents database to classify unknown user agents
- Build a picture of which bots are hitting which pages, how often, and what they're doing
This isn't glamorous work. It's the kind of technical SEO task that falls between teams -- too technical for most marketing teams, not interesting enough for most developers. But the payoff is real: you stop flying blind on a category of traffic that's growing faster than anything else on your site.
What to do with the data once you have it
Identifying AI bot activity is only useful if it changes your behavior. Here's how to think through the decisions:
Decide what to allow and what to block
Not all AI bots deserve the same treatment. A useful framework:
- AI search crawlers (Perplexity, ChatGPT search, Google AI) -- generally allow. These bots index your content to include in AI-generated answers. Blocking them means you won't appear in AI search results.
- Training crawlers (Common Crawl, various LLM training scrapers) -- your call. Allowing them means your content may be used to train models without compensation. Blocking them doesn't guarantee compliance, since many ignore robots.txt.
- Agentic AI (browser-based agents acting on behalf of users) -- context-dependent. A shopping agent browsing your product pages is probably fine. An agent stress-testing your checkout flow is not.
- Unknown or suspicious bots -- block by default, investigate later.
Update your robots.txt
Your robots.txt needs specific directives for specific user agents in 2026. A blanket User-agent: * / Allow: / is no longer adequate. Known Agents provides suggested robots.txt snippets for each bot in its database, which is one of its most practically useful features.
A minimal 2026 robots.txt for a site that wants AI search visibility but wants to block training crawlers might look like:
# Allow AI search crawlers
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /
# Block training crawlers
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Default
User-agent: *
Allow: /
Note that this is a starting point, not a complete solution. The list of AI crawlers changes frequently -- new ones appear, user agents change, and some bots use multiple user agents. Maintaining this list manually is a real ongoing cost.
Connect bot activity to business outcomes
This is where most teams stop short. They get the bot data, they update robots.txt, and they consider the job done. But the more interesting question is: are the AI search crawlers that are visiting your site actually citing you in their responses?
A crawler visit from GPTBot doesn't guarantee that ChatGPT will recommend your brand. The bot might visit your page and decide it's not authoritative enough, not structured well enough, or not relevant enough to cite. Understanding the gap between "AI bot visited this page" and "AI model cited this page" is where the real optimization opportunity lives.
That's where platforms like Promptwatch come in. Promptwatch's AI Crawler Logs feature gives you real-time logs of AI crawlers hitting your site -- which pages they read, errors they encounter, how often they return -- and connects that data to actual citation tracking across ChatGPT, Claude, Perplexity, and other models. You can see whether a page that GPTBot visits frequently is actually getting cited, or whether it's being crawled but ignored.

This closes the loop that server logs and Known Agents alone can't close. Crawler activity is an input. Citations are the output. You need visibility into both to optimize effectively.
The agentic AI problem deserves special attention
Training crawlers and search crawlers are relatively well-understood at this point. Agentic AI is a different beast.
Agentic AI systems -- tools like browser-use, OpenAI's Operator, and various autonomous research agents -- don't just read your pages. They interact with them. They fill out forms, click buttons, navigate multi-step flows, and sometimes complete transactions. They often use headless browser user agents that look identical to regular Chrome traffic.
The 7,851% year-over-year growth in agentic traffic HUMAN Security recorded is almost certainly an undercount, because much of this traffic is indistinguishable from human traffic at the user agent level. You can't block it with robots.txt (agents don't read robots.txt). You can't filter it in analytics (it looks human).
The practical implication: your server logs will show traffic patterns that don't make sense for human behavior -- pages visited in unusual sequences, forms submitted without preceding page views, rapid navigation through checkout flows. These are signals worth investigating.
For now, there's no clean solution to the agentic traffic problem. The best approach is awareness: know it's happening, monitor for anomalous patterns, and make sure your site's forms and APIs have appropriate rate limiting and bot detection in place.
A practical setup for 2026
Here's a realistic implementation plan for a marketing or SEO team that wants to get on top of AI bot activity without becoming a full-time log analyst:
Step 1: Install Known Agents
Takes about five minutes. You get immediate visibility into JS-executing AI bots. Not complete, but a real improvement over nothing.
Step 2: Request server log access
Talk to your hosting provider or dev team. Most hosts retain logs for 30-90 days. Get access to at least a week of logs. If you're on a managed host that doesn't provide log access, this is worth escalating -- it's your data.
Step 3: Parse and classify
Use a log analysis tool to extract bot traffic. Filter by user agent strings that match known AI crawlers. Known Agents' database is a useful reference for what to look for. Look for patterns: which pages are getting crawled most, which bots are most active, any bots hitting pages you'd prefer they didn't.
Step 4: Update robots.txt
Based on what you find, update your robots.txt with specific directives for specific bots. Test it using Google Search Console's robots.txt tester (it works for any user agent, not just Googlebot).
Step 5: Track citations, not just crawls
Set up tracking for where AI models actually cite you. Crawler visits are necessary but not sufficient. You want to know whether those visits are translating into recommendations. This is the step most teams skip, and it's the most valuable one.
Step 6: Review monthly
The AI crawler landscape is changing fast. New bots appear, user agents change, and the behavior of existing bots evolves. A monthly review of your bot logs and robots.txt configuration is a reasonable cadence for most sites.
Tools worth knowing about
Beyond Known Agents and server log analysis, a few other tools are relevant here:
For enterprise-scale log analysis and technical SEO, Botify has long been the standard. It ingests server logs at scale and visualizes crawl behavior across large sites.
For teams that want AI visibility tracking alongside crawler monitoring, Promptwatch's crawler log feature is worth evaluating -- it's one of the few platforms that connects raw crawler activity to actual citation outcomes.
For robots.txt management specifically, the witscode.com guide on robots.txt strategy for 2026 is one of the more thorough references available, covering every major AI crawler and the recommended directives for each.
The bottom line
AI bot traffic is no longer a footnote in your analytics. It's a significant and growing portion of your server load, and the decisions you make about how to handle it have real consequences for your AI search visibility.
DarkVisitors (Known Agents) and server log analysis aren't competing approaches -- they're complementary layers of the same picture. The JavaScript snippet gives you quick, accessible visibility. Server logs give you completeness. Classification databases give you context. And citation tracking tools tell you whether any of it is actually working.
The teams that get this right in 2026 will have a meaningful advantage: they'll know exactly which AI systems are reading their content, which pages are being cited, and where the gaps are. Everyone else will be guessing.