Key takeaways
- Community platforms like Reddit and Quora capture 52.5% of AI citations -- more than brand-owned content across all major AI models
- 73% of websites have technical barriers (robots.txt, CDN rules, JavaScript rendering) that prevent AI crawlers from accessing their content at all
- SERP position #1 earns a 33% AI Overview citation probability; by position #10, that drops to 13% -- a 60% decline
- AI-referred visitors convert at 23x the rate of traditional organic search visitors, making citation quality a direct revenue issue
- Each AI platform (ChatGPT, Perplexity, Google AI Overviews) uses different citation signals -- treating them as one channel is a mistake
- Front-loaded structure, high entity density, and content freshness are the strongest predictors of whether a page gets cited
When someone asks ChatGPT "What's the best CRM for a 50-person SaaS company?", the model doesn't just pick a random answer. It breaks the prompt into sub-queries, retrieves chunks of text from across the web, evaluates those chunks against each other, and assembles a response. The pages that get cited in that response aren't there by accident.
So what actually determines which pages make the cut? In 2026, we finally have enough data to answer that question properly. Several large-scale studies -- including OtterlyAI's analysis of over 1 million citations and The Digital Bloom's citation-to-revenue mapping using data from 30+ research papers -- give us a clearer picture than we've ever had before.
The findings are genuinely surprising in places. And if you're running a marketing or SEO team, some of them should prompt an immediate audit of your current approach.
The citation landscape: who's actually winning
Let's start with the uncomfortable finding. Across ChatGPT, Perplexity, and Google AI Overviews, brand-owned domains account for 47.5% of citations. Community platforms -- Reddit, Quora, and similar forums -- take 52.5%.
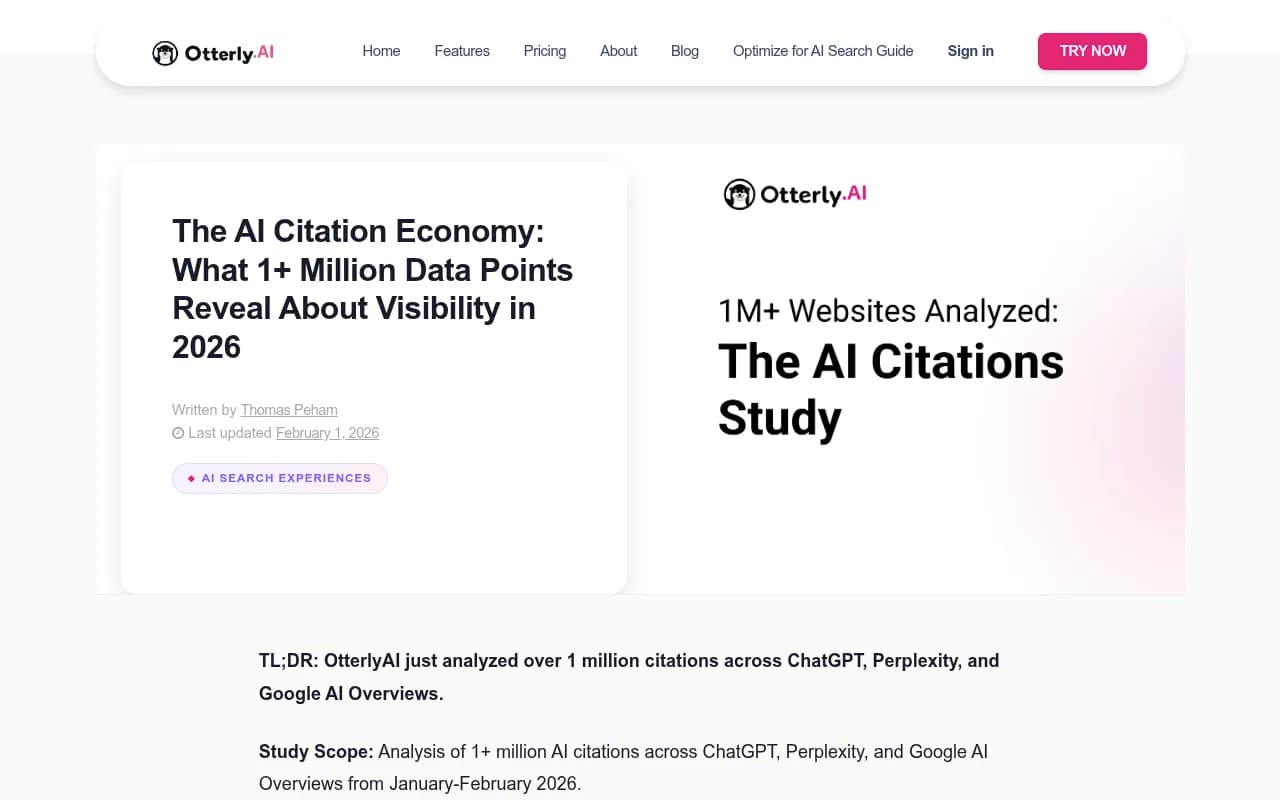
That's not a rounding error. The implication is that when AI models answer questions about your industry, your competitors, or even your own product category, user-generated discussions are more likely to appear than your carefully produced content. News sites add another 20.3% on top of that.
The reason isn't that AI models prefer Reddit for ideological reasons. It's that community content tends to have the specific qualities AI retrieval systems reward: direct answers to specific questions, high entity density, and a format that's easy to chunk into discrete, quotable units. Brand content, by contrast, often reads like marketing copy -- broad, hedged, and structured around what the company wants to say rather than what a user is asking.
Promptwatch tracks citation patterns across 10 AI models and has processed over 1.1 billion citations, giving teams a real-time view of where their content stands versus competitors.

The binary decision AI models make before citing anything
Here's something most people don't realize: before any citation happens, the model makes a binary choice -- answer from memory or search the web. Most users assume ChatGPT always searches. It doesn't.
For well-established facts (capital cities, historical dates, widely known company information), models often answer from training data without triggering a web search at all. No search means no citation opportunity, regardless of how good your content is.
Web search gets triggered when the prompt involves recent events, specific data, product comparisons, or anything where the model's training data might be stale or incomplete. This matters for content strategy: if you want to be cited, you need to be creating content that answers questions AI models consider "search-worthy" -- specific, comparative, time-sensitive, or data-heavy.
Query fan-out: one prompt becomes many searches
When a model does search, it doesn't run one query. It runs several. A prompt like "best project management tools for remote teams" might fan out into sub-queries like "project management software comparison 2026," "remote team collaboration tools," and "Asana vs Monday.com for distributed teams."
Each sub-query can surface different pages. A page that ranks for the broad query might not appear for the specific sub-queries, and vice versa. This is why citation tracking at the prompt level -- not just the keyword level -- matters. You need to know which specific sub-queries your pages are winning.
How SERP position affects citation probability
The connection between traditional search rankings and AI citations is real, but weaker than most people expect.
According to data compiled by The Digital Bloom from multiple 2025-2026 studies, SERP position #1 earns a 33.07% probability of appearing in a Google AI Overview citation. By position #10, that drops to 13.04%. That's a meaningful correlation, but it also means that even the top-ranked page gets ignored two-thirds of the time.
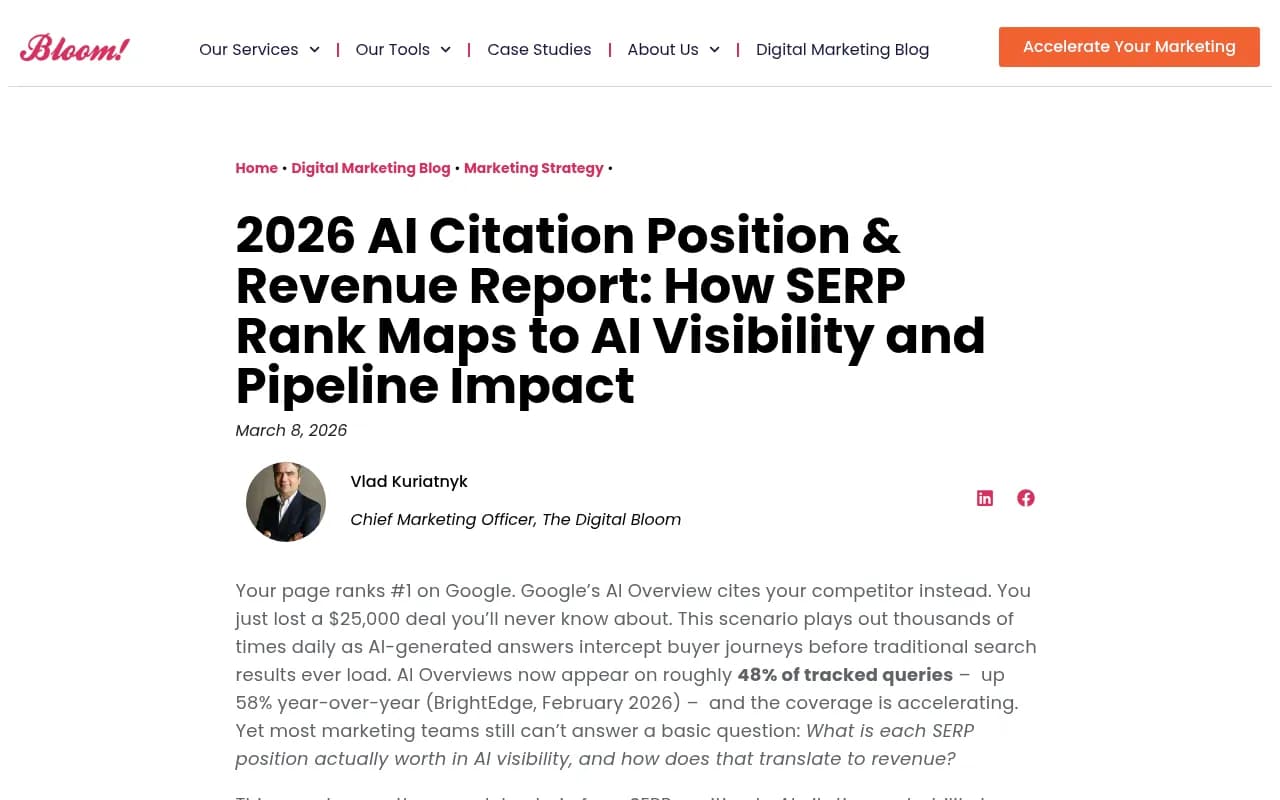
The revenue implications are significant. AI-referred visitors convert at 23x the rate of traditional organic search visitors -- Ahrefs data shows that 0.5% of traffic drove 12.1% of signups. And brands cited in AI Overviews earn 35% higher organic CTR and 91% higher paid CTR compared to uncited brands on the same queries.
At the same time, organic CTR for queries with AI Overviews present dropped 61% -- from 1.76% to 0.61%. So AI citations are simultaneously more valuable per visitor and responsible for fewer visitors reaching your site through traditional clicks. The math still favors optimizing for citation, but it changes how you think about traffic attribution.
What content characteristics predict citations
This is where the research gets most actionable. Several consistent signals emerge across studies.
Front-loaded structure
AI retrieval systems chunk content. They don't read a page the way a human does -- they pull segments and evaluate each segment independently. Pages where the key answer appears in the first 100-150 words of a section get cited more often than pages that bury the answer after extensive setup.
This isn't just about SEO-style "get to the point" advice. It's a technical reality of how retrieval-augmented generation works. If the answer isn't in the chunk the model retrieves, the page won't get cited even if the answer exists somewhere else on the page.
Entity density over depth
Pages with high entity density -- specific named products, companies, people, statistics, and dates -- outperform pages that discuss topics in general terms. An article that says "many companies use project management software to improve efficiency" is less citable than one that says "Asana, Monday.com, and ClickUp each handle task dependencies differently: Asana uses timeline dependencies, Monday.com uses column-based automation..."
Depth matters less than specificity. A 600-word page that answers one question precisely will often outperform a 3,000-word page that covers everything vaguely.
Freshness as a retrieval signal
65% of AI bot hits target content published in the past year. 89% hit content updated within three years. Freshness isn't just a Google ranking factor -- it's a direct input into whether AI crawlers prioritize your pages.
This creates a practical problem for evergreen content strategies. A page you published in 2022 and haven't touched since is at a significant disadvantage, even if the information is still accurate. Regular updates -- even minor ones that add current data or examples -- help maintain crawl priority.
Domain authority still correlates
Higher-authority domains get cited more often. This isn't surprising, but the correlation is weaker than in traditional SEO. A well-structured, specific page on a mid-authority domain can outperform a vague page on a high-authority domain. Authority is a tiebreaker, not a guarantee.
The 73% crawlability problem
Before any of the content quality signals matter, AI crawlers need to actually reach your pages. OtterlyAI's research found that 73% of sites have technical barriers blocking AI crawler access -- robots.txt rules, CDN configurations, or JavaScript rendering requirements that prevent models from reading the content.
This is the most immediately fixable problem for most teams. Check your robots.txt file for rules that block known AI crawlers (GPTBot, ClaudeBot, PerplexityBot, and others). Review your CDN settings for bot-blocking rules. If your content is rendered client-side in JavaScript, AI crawlers may see an empty page.
Tools like DarkVisitors can help you identify which AI crawlers are hitting your site and which are being blocked.
For deeper technical audits, Screaming Frog remains the standard for crawl analysis.
Platform differences: ChatGPT, Perplexity, and Google AI Overviews are not the same
One of the clearest findings from the OtterlyAI study is that citation behavior differs significantly across platforms. Treating them as one channel leads to misallocated effort.
| Platform | Citation style | Primary signal | Key difference |
|---|---|---|---|
| ChatGPT | Clickable inline links | Web search retrieval | Cites more diverse sources; long-tail sites appear frequently |
| Perplexity | Domain-level emphasis | Real-time web index | Rewards recency and specificity; heavy news and forum citations |
| Google AI Overviews | Brand visibility focus | Existing SERP rankings | Strongest correlation with traditional search position |
| Claude | In-response attribution | Training + web search | More conservative; prefers authoritative domains |
| Gemini | Mixed inline/footnote | Google index integration | Closely tied to Google's existing quality signals |
A Reddit thread from the AI Search Lab community noted that across every model tracked, the majority of citations come from sites outside the top 20 search results -- the "long tail" of the web. This is counterintuitive if you're used to thinking about SEO as a top-10 game.
For ChatGPT specifically, the model's web search uses Bing's index. Pages that rank well in Bing but not Google can still get cited. For Perplexity, recency is weighted more heavily than on other platforms. For Google AI Overviews, your existing Google rankings are the strongest predictor of citation probability.
The hallucination problem with citations
It's worth being honest about a real limitation in the current system: AI models get citations wrong. Not rarely -- frequently.
Support rates (the percentage of citations where the cited page actually supports the claim being made) are lower than most users assume. Models sometimes cite pages that are topically related but don't actually contain the specific claim being attributed to them. In other cases, they cite URLs that don't exist at all.
Retrieval-augmented generation (RAG) -- the approach used by ChatGPT with web search, Perplexity, and others -- fixes the URL problem most of the time by grounding citations in actual retrieved content. But it doesn't fix accuracy. A model can retrieve a page, misread a statistic, and cite the page as the source of a claim it never made.
For brands, this creates a monitoring obligation. You need to know not just whether you're being cited, but what claims are being attributed to you. A citation that misrepresents your product's capabilities is worse than no citation at all.
Tools for tracking and improving citation visibility
Understanding the mechanics is one thing. Acting on them requires tooling.
Otterly.AI is one of the more affordable options for monitoring AI citations across multiple platforms.

For teams that want to go beyond monitoring into content gap analysis and optimization, Promptwatch covers the full loop: identifying which prompts competitors are being cited for, generating content designed to earn citations, and tracking whether that content actually moves the needle.
Profound offers strong enterprise-level tracking with good coverage across multiple AI models.

AthenaHQ focuses on tracking across 8+ AI search engines with a clean monitoring interface.

For teams specifically focused on Google AI Overviews alongside traditional SEO, BrightEdge integrates AI visibility tracking into its existing enterprise SEO platform.
Here's a quick comparison of how these tools approach citation tracking:
| Tool | Citation monitoring | Content gap analysis | AI content generation | Crawler logs | Best for |
|---|---|---|---|---|---|
| Promptwatch | Yes (10 models) | Yes | Yes | Yes | Full optimization loop |
| Profound | Yes | Limited | No | No | Enterprise monitoring |
| Otterly.AI | Yes | No | No | No | Budget monitoring |
| AthenaHQ | Yes (8+ models) | No | No | No | Multi-model tracking |
| BrightEdge | Yes (Google focus) | Limited | No | No | Enterprise SEO teams |
What to actually do with this information
The research points to a fairly clear priority order for most teams.
Fix crawlability first. If 73% of sites have barriers blocking AI crawlers, there's a good chance yours does too. This is a technical fix that costs nothing but time and can immediately improve your citation eligibility.
Audit your content structure. Go through your highest-value pages and check whether the key answer appears in the first paragraph of each section. If you're burying the lede, restructure. This applies especially to comparison pages, FAQ content, and anything that answers a specific "which" or "how" question.
Update stale content. Identify pages that haven't been touched in over a year and add current data, examples, or statistics. Even minor updates reset the freshness signal.
Build entity-rich pages. For topics where you want to be cited, create pages that name specific products, include specific numbers, and answer specific questions -- not pages that discuss the topic in general terms.
Monitor platform-specifically. Don't assume that what works for Google AI Overviews will work for Perplexity or ChatGPT. Track your citation performance on each platform separately and look for patterns in what's getting cited where.
The underlying shift here is real: AI search is becoming a distinct channel with its own signals, its own citation economy, and its own winners. The brands building infrastructure to understand and optimize for that channel now are accumulating an advantage that will compound as AI search continues to grow. Google AI Overviews now appear on roughly 48% of tracked queries -- up 58% year-over-year. That number isn't going down.