Key takeaways
- AI search is now fragmented across 10+ models, each with different training data, citation behavior, and user bases -- tracking only one gives you a dangerously incomplete picture.
- 15% of website traffic now originates from AI agents and bots, with ChatGPT driving 56% of AI referral traffic, Gemini 18%, and Perplexity 8% -- but those shares shift constantly.
- Enterprise brands need to monitor not just whether they're mentioned, but where citations come from, which competitors are winning specific prompts, and how visibility translates to actual traffic.
- Most monitoring tools stop at showing you data. The gap that matters in 2026 is between knowing you're invisible and doing something about it.
- Multi-LLM tracking, crawler log analysis, and content gap identification are now table stakes for any enterprise AI search strategy.
The fragmentation problem nobody warned you about
A year ago, most enterprise marketing teams were asking "should we care about AI search?" That question is settled. The new question is harder: "Which AI search engines are we actually visible in, and why does it vary so much between them?"
Here's what's happening. ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, Grok, Copilot, DeepSeek, Meta AI -- these aren't interchangeable. They use different training data, different retrieval architectures, different citation logic, and they serve meaningfully different user populations. A brand that appears confidently in ChatGPT responses might be almost invisible in Perplexity, and vice versa. A competitor that barely registers in Google AI Overviews might dominate Gemini for the exact same query.
If you're only tracking one model, you're not doing AI search monitoring. You're doing a spot check.
This matters more than it sounds. According to research from OtterlyAI, 15% of all website traffic now comes from AI agents and bots. ChatGPT accounts for 56% of AI search referral traffic, Gemini for 18%, and Perplexity for 8%. Those numbers look like ChatGPT dominates, so why bother tracking the others? Because that 44% outside ChatGPT represents real users, real queries, and real revenue -- and because those shares are not stable. The model that's third today could be first in six months.
Enterprise brands that only monitor ChatGPT are making a bet that the current market share distribution is permanent. That's a bet worth examining carefully.
Why AI models disagree with each other
Before getting into monitoring strategy, it's worth understanding why different AI models produce such different results for the same brand query.
Training data cutoffs vary. A model trained on data through late 2024 has a different picture of your brand than one with a 2025 cutoff. If you launched a major product, rebranded, or got significant press coverage in 2025, some models know about it and others don't.
Retrieval augmentation works differently across models. Perplexity is fundamentally a retrieval-augmented system -- it's actively searching the web when it answers. ChatGPT's web browsing is more selective. Google AI Overviews pulls from Google's index. Claude uses a mix of training data and, in some configurations, real-time retrieval. The sources each model trusts, and how it weights them, differ substantially.
Citation logic isn't uniform. Some models prefer to cite authoritative domains. Others weight recency. Some pull heavily from Reddit and forums. Others prefer structured editorial content. The same underlying facts about your brand might get cited from different sources depending on which model is answering.
Persona and context matter too. A query about "best enterprise CRM" asked in ChatGPT by someone in a business context might produce different results than the same query in Gemini, partly because of how each model interprets the likely intent.
The practical implication: your brand's AI visibility isn't a single number. It's a matrix of scores across models, query types, and contexts. Treating it as a single number is the monitoring equivalent of reporting "average temperature" as your only weather metric.
What enterprise monitoring actually needs to cover
Multi-model coverage
This is the obvious starting point. Your monitoring infrastructure needs to track responses across at least the major models: ChatGPT, Perplexity, Google AI Overviews, Gemini, Claude, and Copilot at minimum. Grok, DeepSeek, Meta AI, and Mistral are increasingly relevant depending on your audience.
The important nuance here is that you need to track these models as users actually experience them -- not just through API calls. User-facing interfaces can produce different answers than API outputs, particularly for shopping recommendations, local results, and anything where the model is doing real-time retrieval.
Prompt coverage that reflects real user behavior
Most enterprise brands start with a handful of branded queries ("what is [brand name]?", "[brand] vs [competitor]") and call it done. That's a starting point, not a strategy.
Real AI search monitoring needs to cover the full range of prompts your potential customers are actually using: category queries, problem-based queries, comparison queries, use-case queries. "What's the best project management software for remote teams?" is a more commercially important prompt than "what is Asana?" -- and your visibility in the former is what actually drives discovery.
Prompt volume and difficulty scoring help prioritize. Not all prompts are equally worth winning, and not all are equally winnable. A good monitoring setup tells you which prompts have high query volume, which competitors are currently winning them, and which ones you have a realistic path to capturing.
Citation and source analysis
Being mentioned in an AI response is one thing. Understanding why you're being mentioned -- and why you're not being mentioned in other responses -- requires citation analysis.
Which pages on your site are AI models citing? Which third-party sources (review sites, industry publications, Reddit threads, YouTube videos) are driving your AI visibility? Which competitor pages are getting cited instead of yours?
This matters because it tells you where to focus. If Perplexity is citing a three-year-old TechCrunch article about your company while ignoring your current product pages, that's a specific, fixable problem. If a competitor is getting cited because they have a detailed comparison page that you don't, that's a content gap you can close.
AI crawler log analysis
This is the capability most enterprise teams don't know they're missing. AI search engines send crawlers to your website -- ChatGPT's crawler, Claude's crawler, Perplexity's crawler -- and what those crawlers find (or fail to find) directly affects what gets cited.
Crawler log analysis tells you which pages AI bots are visiting, how often they return, what errors they're encountering, and how long it takes for a crawled page to start appearing in citations. If your most important product pages are returning errors to AI crawlers, or if crawlers are ignoring them entirely, you have an indexing problem that no amount of content optimization will fix.
Most monitoring tools don't surface this data at all. It requires either server log access, a CDN integration (Cloudflare, Fastly, Vercel), or a tracking snippet -- and the willingness to actually look at what the logs reveal.
Competitive visibility comparison
Your AI visibility score in isolation is almost meaningless. What matters is your visibility relative to competitors, across specific prompts, in specific models.
A competitor heatmap -- showing who's winning each prompt in each model -- is one of the most actionable outputs of enterprise AI monitoring. It tells you where you're losing ground, which competitors are gaining, and which models are most vulnerable to competitive displacement.
Traffic attribution
The final piece is connecting AI visibility to actual business outcomes. AI citations that don't drive traffic are interesting but not valuable. Traffic that doesn't convert is similarly limited.
Enterprise monitoring needs to close the loop: which AI citations are driving sessions, which sessions are converting, and what's the revenue impact of your AI visibility improvements over time. This requires integration with your analytics stack, not just a standalone monitoring dashboard.
The monitoring-only trap
Here's a pattern that's become common in 2026: enterprise teams invest in AI search monitoring, generate impressive dashboards showing their visibility scores across models, and then... don't know what to do next.
The data shows they're invisible for 60% of their target prompts. Competitors are winning the queries that matter most. But the monitoring tool stops there. It shows you the problem without helping you solve it.
This is the fundamental limitation of most monitoring-only platforms. They're built to measure, not to act. And measurement without action is just expensive anxiety.
The more useful framing is to think of AI search monitoring as the first step in a loop, not the destination. You monitor to find gaps. You use those gaps to prioritize content creation. You create content engineered to answer the specific questions AI models are exposing. You track whether that content gets crawled, cited, and whether citations drive traffic.
Promptwatch is built around this loop explicitly -- the Answer Gap Analysis shows which prompts competitors are visible for that you're not, Content Agents generate articles and briefs grounded in that gap data, and page-level tracking shows when new content starts getting cited. It's the difference between a monitoring dashboard and an optimization platform.

How different tools approach enterprise monitoring
The tool landscape in 2026 has matured considerably, but there's still a wide range in what "AI search monitoring" actually means in practice.
Here's a realistic comparison of what enterprise teams should expect from different categories of tools:
| Capability | Basic monitoring tools | Mid-tier platforms | Enterprise platforms |
|---|---|---|---|
| Multi-LLM coverage | 2-3 models | 4-6 models | 8-10+ models |
| Prompt volume data | No | Sometimes | Yes |
| Crawler log analysis | No | Rarely | Yes |
| Content gap analysis | No | Basic | Advanced |
| Content generation | No | No | Yes (some) |
| Traffic attribution | No | No | Yes (some) |
| Competitor heatmaps | Basic | Yes | Advanced |
| Reddit/YouTube tracking | No | Rarely | Yes (some) |
| ChatGPT Shopping tracking | No | No | Yes (some) |
| API/data export | Rarely | Sometimes | Yes |
The gap between "basic monitoring" and "enterprise platform" is significant. For a brand managing multiple product lines, multiple markets, and multiple competitors, the basic tier simply doesn't provide enough signal to make decisions.
Some tools worth knowing in this space:
Profound is a strong enterprise-focused option with solid LLM analysis capabilities, though at higher price points than some alternatives.

AthenaHQ covers 8+ AI search engines and is monitoring-focused, which works well for teams that have separate content workflows.

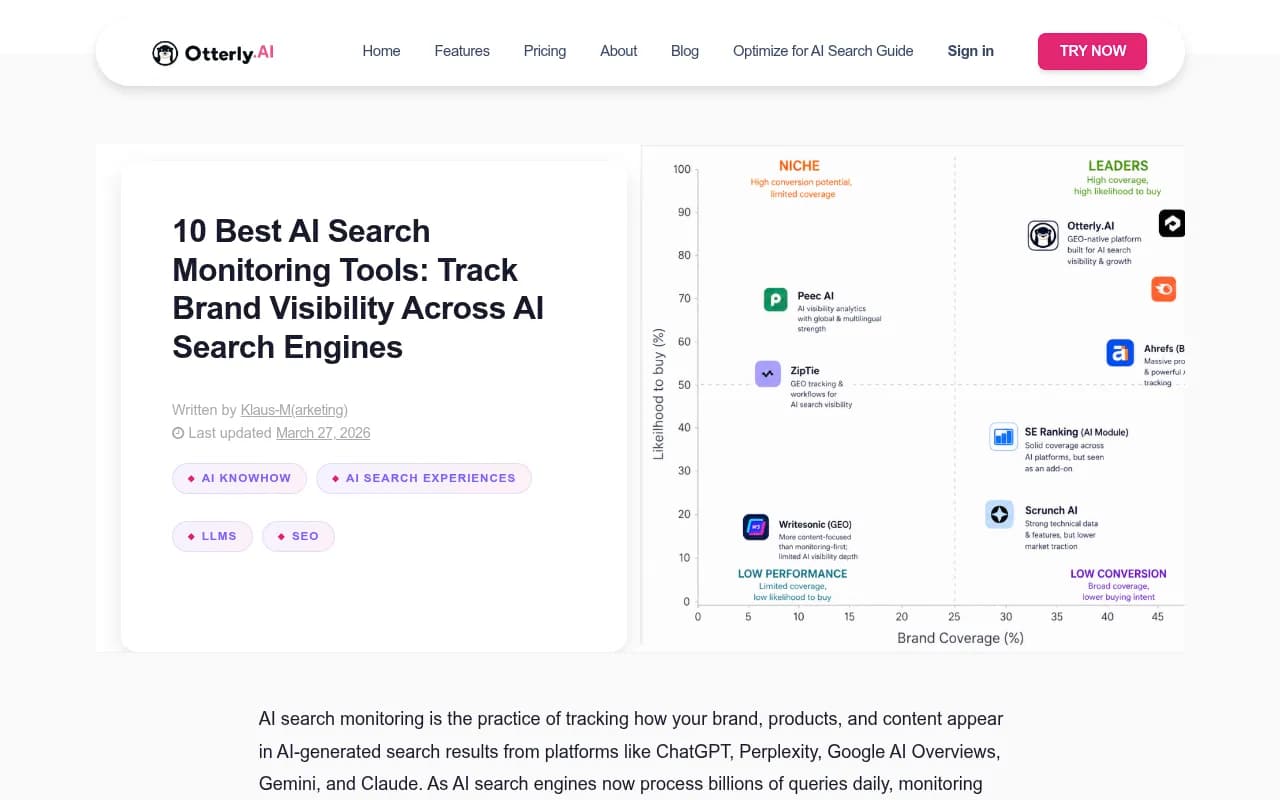
Otterly.AI is a well-established monitoring platform that's been in this space since early, with good coverage of the major models.

Peec AI offers multi-language tracking, which matters for enterprise brands operating across regions.

Nightwatch combines traditional SEO monitoring with LLM tracking, which can be useful for teams that don't want to manage separate tools.
Scrunch AI focuses on AI search visibility monitoring with a clean interface for tracking brand mentions across models.
BrightEdge brings its enterprise SEO heritage to AI visibility tracking, which can be valuable for large organizations already in their ecosystem.
seoClarity is another enterprise SEO platform that has added AI search visibility tracking to its existing suite.
Building a practical multi-LLM monitoring strategy
Start with your most commercially important prompts
Don't try to monitor everything at once. Start with the 20-30 prompts that most directly reflect how your target customers discover solutions like yours. These are usually category queries ("best [category] software for [use case]"), comparison queries ("[your brand] vs [competitor]"), and problem-based queries ("how to solve [problem your product addresses]").
Get a baseline visibility score across your target models for these prompts. This is your starting point.
Identify the model where you're most underperforming
You'll almost certainly find that your visibility varies significantly across models. Pick the model where the gap between your visibility and your competitors' visibility is largest -- that's usually where you have the most to gain.
Understand why you're underperforming there. Is it a content issue (you don't have pages that answer the relevant questions)? A citation source issue (the sources that model trusts don't mention you favorably)? A crawler access issue (the model's bot isn't reaching your relevant pages)?
Fix the most tractable problems first
Content gaps are usually the most tractable. If competitors are getting cited for a query because they have a detailed guide on the topic and you don't, you can write that guide. If a competitor's comparison page is getting cited instead of yours, you can create a better one.
Crawler access issues are also fixable -- check your robots.txt, ensure AI crawlers aren't being blocked, fix any server errors that AI bots are encountering.
Third-party citation issues (you're not being mentioned in the review sites, forums, and publications that AI models trust) are harder but addressable through PR, community engagement, and strategic content placement.
Track the full cycle from publish to citation
When you create new content to address a gap, don't just wait and hope. Track whether AI crawlers are visiting the new page, when they first crawl it, and when it starts appearing in citations. This feedback loop tells you whether your content strategy is working and how long the lag is between publishing and visibility.
Report on share of model, not just absolute visibility
For executive reporting, "share of model" -- the percentage of relevant prompts where your brand appears in AI responses, compared to competitors -- is a more meaningful metric than raw citation counts. It's the AI equivalent of share of voice, and it's the number that tells you whether you're winning or losing ground.
The multi-region and multi-language dimension
For enterprise brands operating internationally, the complexity multiplies. AI models don't just vary by model -- they vary by region and language. A brand that's well-cited in English-language ChatGPT responses might be almost invisible in French or German responses, even from the same model.
This matters because AI models often have different training data distributions across languages, and the sources they trust in different languages can be completely different. The SEO authority you've built in English doesn't automatically transfer.
Multi-region monitoring requires tracking the same prompts across different country/language combinations, which multiplies the monitoring surface area significantly. Most basic tools don't support this. Enterprise platforms that do -- with customizable personas that reflect how customers in different markets actually prompt -- are worth the premium for brands with meaningful international revenue.
What to look for when evaluating enterprise tools
A few questions worth asking any vendor:
- Do you monitor user-facing interfaces or just APIs? (The answer matters for accuracy.)
- Which AI crawlers do you track in your crawler logs, and how do you identify them?
- How do you handle prompt volume estimation -- is it modeled or measured?
- Can you track visibility at the page level, not just the domain level?
- How do you attribute AI-driven traffic back to specific citations?
- What's your data refresh frequency, and is it consistent across all models you monitor?
- Do you support multi-region and multi-language monitoring?
The answers will quickly separate tools that are genuinely built for enterprise use from those that have "enterprise" in their marketing but not in their architecture.
The bottom line
Single-LLM tracking made sense in 2024 when ChatGPT was the only AI search engine most people were using. In 2026, it's a blind spot. The AI search landscape is genuinely fragmented, and that fragmentation is growing, not shrinking.
Enterprise brands that are serious about AI visibility need monitoring infrastructure that covers the full model landscape, goes below the surface to understand why visibility varies, and connects monitoring data to content action and business outcomes. The brands that figure this out in the next 12 months will be significantly harder to displace in AI search than those that are still running spot checks on a single model.
The tools exist. The data is available. The gap is in treating AI search monitoring as a strategic capability rather than a dashboard to check occasionally.