Key takeaways
- When a user asks ChatGPT a question, the model fires multiple sub-queries behind the scenes -- this is called query fan-out. Your content needs to answer all of them, not just the primary keyword.
- Fan-out data is essentially a map of what ChatGPT is looking for but can't find on your site -- making it one of the most direct inputs for content gap analysis available in 2026.
- You can extract fan-out queries manually (by watching ChatGPT's search behavior in real time) or systematically using platforms that track prompt-level AI search behavior.
- The fix isn't always a new page -- sometimes it's a missing section, a different format, or content published on Reddit or YouTube rather than your own domain.
- Platforms like Promptwatch surface fan-out data alongside answer gap analysis, so you can go from "ChatGPT isn't citing us" to "here's the exact content we need to create" in one workflow.
What query fan-out actually means (and why it matters now)
Most SEOs spent years optimizing for a single keyword per page. That mental model is now genuinely broken for AI search.
When someone asks ChatGPT "What's the best way to save for retirement?", the model doesn't just look up that phrase. It fans out into a cluster of related searches: 401(k) contribution limits for 2026, Roth IRA vs traditional IRA comparison, retirement savings by age benchmarks, common retirement planning mistakes, and more. Each of those sub-queries pulls in sources independently. The final answer ChatGPT gives is synthesized from all of them.
If your site answers the main question but misses three of the sub-queries, you might get cited once -- or not at all, because a competitor's more complete coverage wins the synthesis.
This is what makes fan-out data so valuable. It's not theoretical. It's a direct window into what the model is actually searching for when your topic comes up.

Source: iPullRank's guide on query fan-out -- a useful breakdown of how one prompt branches into a full content strategy.
How to see fan-out queries in ChatGPT
The good news: ChatGPT shows you its work, at least partially.
When ChatGPT Search is active (the globe icon in the interface), you can watch it run searches in real time. Each search it fires is a fan-out query. GPT-4o and GPT-5 both do this, though the way they display it has changed over time.
Manual extraction method
- Open ChatGPT with web search enabled.
- Ask a question relevant to your business -- something a real customer would ask.
- Watch the "Searching..." steps as they appear. Each one is a sub-query.
- Screenshot or copy each query before the final answer loads.
- Repeat with variations of the same prompt (different phrasings, different personas, different levels of specificity).
This is slow but free. For a handful of priority topics, it's worth doing manually at least once so you understand what you're dealing with.
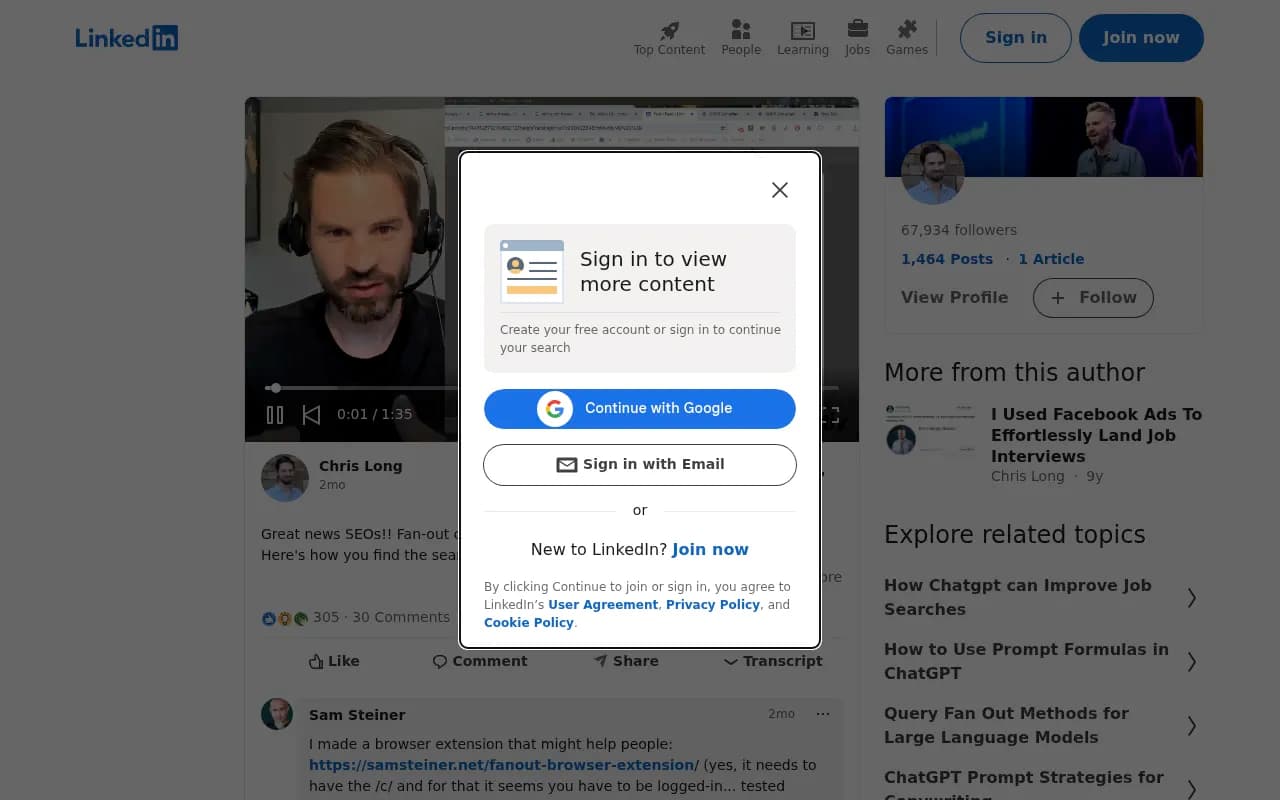
SEO consultant Chris Long documented the return of visible fan-out queries in ChatGPT -- a useful signal that the model's search behavior is now more transparent than it was in 2024.
Systematic extraction at scale
Manual extraction breaks down fast when you're tracking dozens of topics across multiple competitors. At that point you need a platform that monitors AI search behavior systematically.
Promptwatch tracks how ChatGPT, Perplexity, Gemini, and other AI engines respond to prompts at scale -- including the sub-queries they fire. Its Prompt Intelligence feature shows volume estimates and difficulty scores per prompt, plus the query fan-outs that branch from each one.

Tools like Peec AI also publish research on fan-out patterns, which is worth reading even if you don't use their platform.

The reverse-engineering process: from fan-out to content gap
Once you have a list of fan-out queries for a topic, the actual work begins. Here's a practical process.
Step 1: Map the fan-out cluster
Take one primary prompt -- something your target audience would actually type into ChatGPT -- and extract every sub-query you can find. Group them into themes. For a B2B software company targeting "best project management tools for remote teams," the fan-out might include:
- Feature comparisons (Asana vs Monday vs Notion)
- Pricing breakdowns
- Integration compatibility (Slack, Google Workspace, etc.)
- Reviews from specific user types (small teams, agencies, enterprises)
- "Reddit recommends" style queries
- Video walkthroughs and tutorials
That's six distinct content categories from one prompt. Each one is a potential gap.
Step 2: Check what's currently winning each sub-query
For each fan-out query, look at what ChatGPT actually cites. This is where citation analysis becomes essential. You want to know:
- Is your site cited for any of these sub-queries?
- Which competitors are cited, and for which sub-queries?
- What format is being cited -- a blog post, a Reddit thread, a YouTube video, a comparison page?
This step is hard to do manually at scale. Platforms that track citations across AI models make it much faster.

Step 3: Identify the gaps on your site
Cross-reference the fan-out cluster against your existing content. Be honest. A page that vaguely mentions pricing isn't the same as a page that directly answers "how much does [product] cost for a team of 10?" -- the latter is what ChatGPT wants.
Common gap patterns:
- You have a features page but no comparison content
- You cover the topic but not the specific persona (e.g., you write for enterprise but the fan-out is pulling SMB-focused content)
- You have the information but it's buried in a long article rather than surfaced in a scannable format
- The winning source isn't a website at all -- it's a Reddit thread or a YouTube video
Step 4: Prioritize by impact
Not all gaps are equal. A sub-query that appears in 80% of fan-outs for your primary topic is more important than one that shows up occasionally. Prompt volume data helps here -- some platforms assign estimated query volumes to individual prompts, which lets you prioritize the gaps most likely to drive visibility.
What format does ChatGPT actually want?
Fan-out data tells you what to cover. Citation patterns tell you how to cover it.
Research from Peec AI on ChatGPT query fan-out patterns found that "best of" listicles consistently win citations, particularly when they're structured with clear headings, specific product names, and direct comparisons. Review sites and aggregator pages also punch above their weight because they satisfy multiple sub-queries at once.
That said, format preferences vary by query type:
| Query type | Winning format | Why it works |
|---|---|---|
| Comparison ("X vs Y") | Side-by-side table or structured comparison | Directly answers the sub-query without requiring synthesis |
| "Best for" queries | Listicle with use-case headers | Matches how AI models categorize recommendations |
| How-to / process | Step-by-step with numbered lists | Easy to extract and cite as a discrete answer |
| Pricing / specs | Dedicated pricing page or FAQ | Specific, factual, easy to verify |
| Reviews / opinions | Third-party mentions (Reddit, G2, YouTube) | AI models weight external validation heavily |
| Local / regional | Location-specific pages | Fan-outs often include geo-qualifiers |
The implication: you probably need more comparison content, more structured listicles, and more presence on third-party platforms than you currently have.
Offsite gaps are just as real as onsite gaps
This is the part most teams miss. When you look at what ChatGPT cites for a given fan-out query, a significant portion of citations often come from Reddit, YouTube, G2, Trustpilot, or industry publications -- not the brand's own website.
If your brand isn't mentioned in those places, no amount of on-site optimization will fix your AI visibility for those sub-queries. The model is pulling from wherever the best answer lives.
Practical implications:
- Seed Reddit threads in relevant subreddits where your product genuinely helps. Don't spam -- answer questions well, and your brand name starts appearing in the discussions AI models pull from.
- Publish YouTube content that directly answers the sub-queries in your fan-out cluster. Titles matter: "Asana vs Monday for Remote Teams in 2026" is a fan-out query, not just a YouTube title.
- Get listed and reviewed on G2, Capterra, and category-specific directories. These pages get cited constantly.
- Pitch industry publications for comparison roundups. A mention in a "best tools for X" article from a credible domain carries real weight.
Promptwatch's offsite citation analysis tracks which external pages -- Reddit threads, YouTube videos, third-party listicles -- are driving AI citations for your category, so you can see exactly where to invest outside your own site.
Building a content plan from fan-out data
Once you've mapped the gaps, you need a way to turn them into actual content. Here's a simple framework.
Tier 1: Fix existing pages first
Before creating anything new, audit your current content against the fan-out cluster. Often you can add a section, restructure a heading, or add a comparison table to an existing page and close a gap without writing a whole new article. This is faster and preserves existing authority.
Tier 2: Create targeted gap-filling content
For gaps that can't be addressed by updating existing pages, create new content specifically designed to answer the sub-query. The key difference from traditional SEO content: you're not writing for a keyword, you're writing to answer a specific question that AI models are already searching for. That means:
- The answer to the sub-query should appear early and clearly
- Use the exact phrasing from the fan-out query in your headings
- Include structured data where relevant (FAQ schema, HowTo schema, etc.)
- Keep the content focused -- a 400-word page that directly answers one sub-query often beats a 3,000-word guide that mentions it in passing
Tier 3: Build offsite presence for gaps you can't own
For sub-queries where third-party sources dominate and you can't realistically outrank them on your own site, focus on getting mentioned within those sources. This is a longer play but it's the right one.
Tools that help with fan-out analysis
The manual process described above works, but it doesn't scale. Here are the tools worth knowing about.
For tracking fan-out queries and prompt-level AI behavior:

For content gap analysis and brief generation:
For offsite citation and Reddit/YouTube tracking:
Promptwatch includes Reddit and YouTube insights as part of its citation analysis -- useful for identifying which offsite content is already influencing AI responses in your category.
For monitoring which pages on your site are being crawled and cited by AI agents:
Promptwatch's AI Crawler Logs show which pages ChatGPT, Perplexity, and Claude are actually reading, how often they return, and when a crawled page moves to a citation. This closes the loop between "we published content" and "AI is now citing it."
A comparison of approaches
| Approach | Cost | Scale | Best for |
|---|---|---|---|
| Manual ChatGPT observation | Free | Very low | Initial exploration, 1-5 topics |
| Prompt tracking platform (Promptwatch, Rankscale) | $99-$579/mo | High | Ongoing monitoring across many topics |
| Citation analysis tools | Varies | Medium-High | Understanding what's winning each sub-query |
| Content gap platforms (Frase, MarketMuse) | $45-$400/mo | Medium | Brief generation and content planning |
| Manual Reddit/YouTube research | Free | Low | Offsite gap identification |
The actual workflow, condensed
- Pick a primary prompt your customers use with ChatGPT.
- Extract the fan-out sub-queries (manually or via a tracking platform).
- For each sub-query, check what ChatGPT cites -- your site, competitors, or third-party sources.
- Map the gaps: which sub-queries have no answer on your site?
- Prioritize by frequency and estimated query volume.
- Fix existing pages where possible; create new content where necessary.
- Build offsite presence for sub-queries dominated by Reddit, YouTube, or review sites.
- Track citation changes over time to see which content is getting picked up.
The whole point of this process is that it's grounded in what AI models are actually searching for, not what you assume they want. Fan-out data removes the guesswork. Your content gaps aren't hypothetical -- they're the specific questions ChatGPT is already asking that your site can't answer.
That's a solvable problem, and the data to solve it is more accessible in 2026 than it's ever been.